CS/운영체제
10. File System Implementation
호프
2023. 12. 19. 03:33
Allocation of File Data in Disk
- File은 크기가 균일하지 않기 때문에 동일한 크기 단위인 sector로 나누어 저장 (메모리 관리 기법 중 페이징 기법과 유사)
Contiguous Allocation
Contiguous Allocation
- 하나의 파일이 디스크 상에 연속해서 저장되는 방식으로, 나누어진 각 블록들이 연속된 번호를 부여 받아 저장된다.
Pros
- Fast I/O (대부분의 접근 시간은 헤더가 움직이면서 읽어들이는 시간)
- 한번의 seek/rotation으로 많은 바이트 transfer 가능 (모두 연속해서 붙어있으므로)
- Realtime file (공간효율성보다 속도 효율성이 더 중요할 때) 또는 이미 run 중이던 process의 swapping 용으로 사용 (프로세스의 주소공간 중 일부를 저장하는 용도)
- Direct access(=random access) 가능
Cons
- external fragmentation 발생
- File grow 어려움(file size 확장 한계)
- file 생성 시 얼마나 큰 hole을 배당할 것인가
- grow를 가능하게 할 수록 공간 낭비 발생 (internal fragmentation)
👉 효율성이 떨어진다 (Optimization 측면)
Linked Allocation
Linked Allocation
- sector들이 각각 node가 되어 Linked List 구조를 취하면서 파일을 저장한다.
Pros
- External fragmentation 발생하지 않는다.
Cons
- No random access: 첫 요소부터 차례대로 읽어야 하기 때문
- Reliability 문제
- 한 sector가 고장나 pointer가 유실되면 많은 부분을 잃게 됨
- Pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨림
- 512 bytes/sector, 4 bytes/pointer
변형: File-allocation table (FAT)
- 포인터를 별도의 위치에 보관하여 신뢰성 문제와 공간 효율성 문제를 해결하는 파일 시스템
Indexed Allocation
Indexed Allocation
- 파일이 어디에 나눠져 있는지 인덱스를 적어두는 블록 하나(Index Block)를 활용
Pros
- External fragmentation이 발생하지 않는다.
- Direct access 가능
Cons
- Small file의 경우 공간 낭비가 심하다 (실제로 많은 파일들 small)
- Too large file의 경우 하나의 block으로 index를 저장하기에 부족
- linked schema: 여러 Index block을 사용하고 pointer로 index block을 연결하는 방법
- multi-level index: 인덱스를 위한 인덱스를 사용하는 방법 (블록의 마지막에 다음 index 블록을 가리키는 값을 설정하여 서로 연결)
File System 구조
UNIX (LINUX)
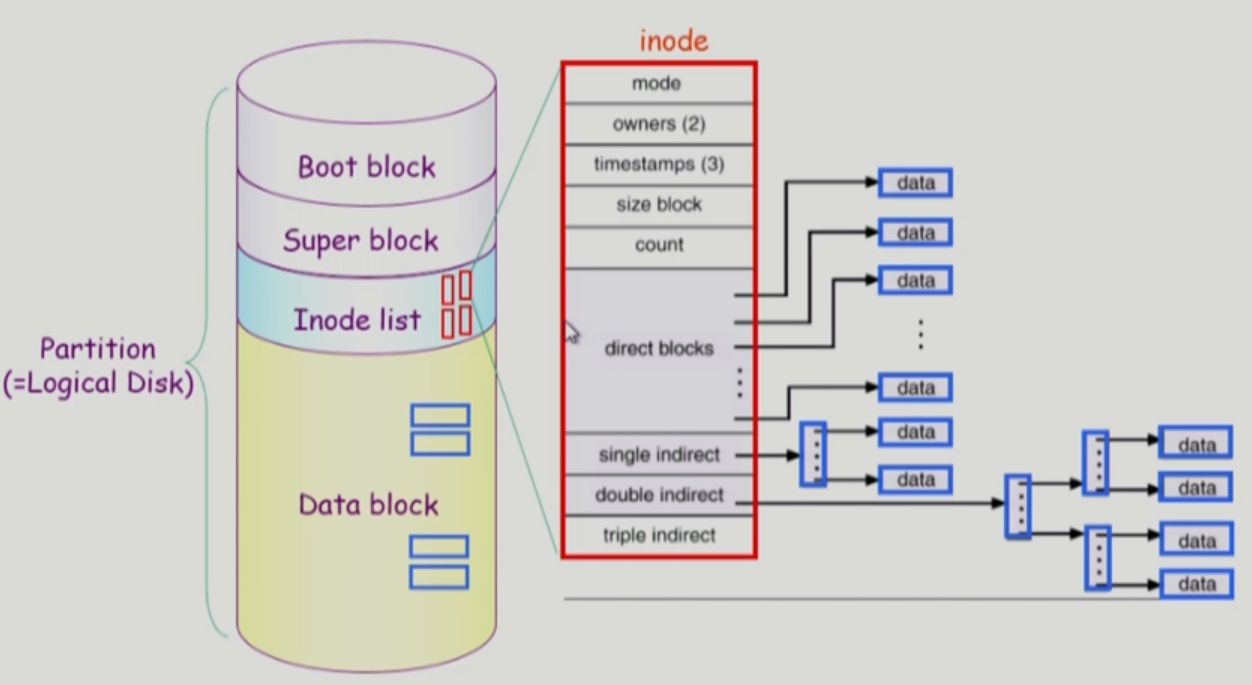
Boot block
- 부팅에 필요한 정보 저장 (bootstrap loader)
- 모든 파일 시스템에 존재하는 블록
Superblock
- 파일 시스템에 관한 총체적인 정보 저장
- metadata의 metadata 저장
Inode list
- 파일 하나 당 하나의 Inode 할당 -> 파일 이름을 제외한 파일의 모든 메타데이터를 저장
- 파일의 이름은 디렉토리가 저장 -> 디렉토리는 파일의 이름과 Inode 번호를 저장
- direct blocks: 파일이 존재하는 인덱스를 저장하는 인덱스 블록(직접 indexing) - 파일의 크기가 작은 경우 해당 블록을 이용하여 파일 접근
- direct blocks로 커버할 수 있는 크기보다 큰 파일은 single indirect를 통해서 하나의 level을 두어 저장, 그보다 더 큰 파일은 double indirect, triple indirect 이용
Data block
- 파일의 실제 내용을 보관
- 디렉토리 파일은 자신의 디렉토리에 속한 파일들의 이름과 Inode 번호를 가지고 있음
MS-DOS (Windows) - FAT 파일 시스템

- 파일의 메타데이터의 일부(위치 정보)를 FAT에 저장하고, 나머지 정보는 디렉토리가 가지고 있음
- 사진 속 예제에서 217번이 첫 번째 블록 -> 다음 블록의 위치를 FAT에 별도로 관리
- FAT는 중요한 정보이므로 복제본을 만들어 두어야 한다
Free-Space Management
sector가 할당되고 나서 발생하는 hole을 어떻게 관리할 것인가?
Bit map or Bit vector
if block[i] == free:
bit[i] = 0
else if block[i] == occupied:
bit[i] = 1- Pros: 연속적인 n개의 free block을 찾는데 효과적
- Cons: Bit map은 부가적인 공간을 필요로 함
Linked List
- 모든 free block들을 링크로 연걸 (free list)
- Pros: 공간의 낭비가 없다
- Cons: 연속적인 가용공간을 찾는 것이 쉽지 않다
Grouping
- Linked list 방법의 변형: 첫번째 free block이 n개의 pointer를 가짐
- 0 ~ n - 1 pointer는 free data block을 가리킴
- 마지막 pointer가 가리키는 block은 또 다시 n pointer를 가짐
- 로직이 복잡하다는 단점
Counting
- 프로그램들이 종종 여러 개의 연속적인 block을 할당하고 반납한다는 성질에 착안
- (first free block, # of contiguous free blocks)를 유지
Directory Implementation
디렉토리 구현 방법
Linear List
- <file name, file metadata> 의 list
- Pros: 구현 간단
- Cons: 디렉토리 내에 파일이 있는 지 찾기 위해 linear search 필요 (time-consuming)
Hash Table
- linear list + hashing
- Hash table은 file name을 이 파일의 linear list의 위치로 바꾸어줌
- Pros: search time을 없앰
- Cons: collision 발생 가능

File의 metadata 보관 위치
- 디렉토리 내에 직접 보관
- 디렉토리에는 포인터를 두고 다른 곳에 보관
- Inode, FAT
- 단점: 저장 공간이 많이 필요하고 관리 복잡
- 장점: fragmentation X
Long file name 지원
- <file name, file metadata> list에서 각 entry 크기는 일반적으로 고정
- file name이 고정 크기 entry 길이보다 길어지는 경우 entry의 마지막 부분에 이름의 뒷부분이 위치한 곳의 포인터를 두는 방법 사용
- 이름의 나머지 부분은 동일한 directory file의 일부에 존재
File System
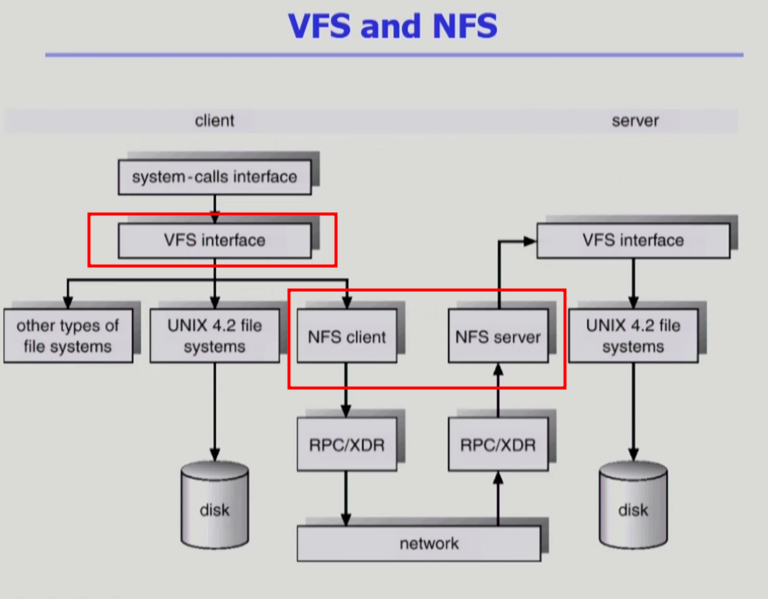
VFS and NFS
Virtual File System (VFS)
- 서로 다른 다양한 file system에 대해 동일한 시스템 콜 인터페이스(API)를 통해 접근할 수 있게 해주는 OS의 layer
- 어떤 파일 시스템을 쓰든 상관 없이 VFS 인터페이스를 사용
Network File System (NFS)
- 분산 시스템에서는 네트워크를 통해 파일이 공유될 수 있음
- NFS는 분산 환경에서의 대표적인 파일 공유 방법
- NFS client와 NFS server 사용
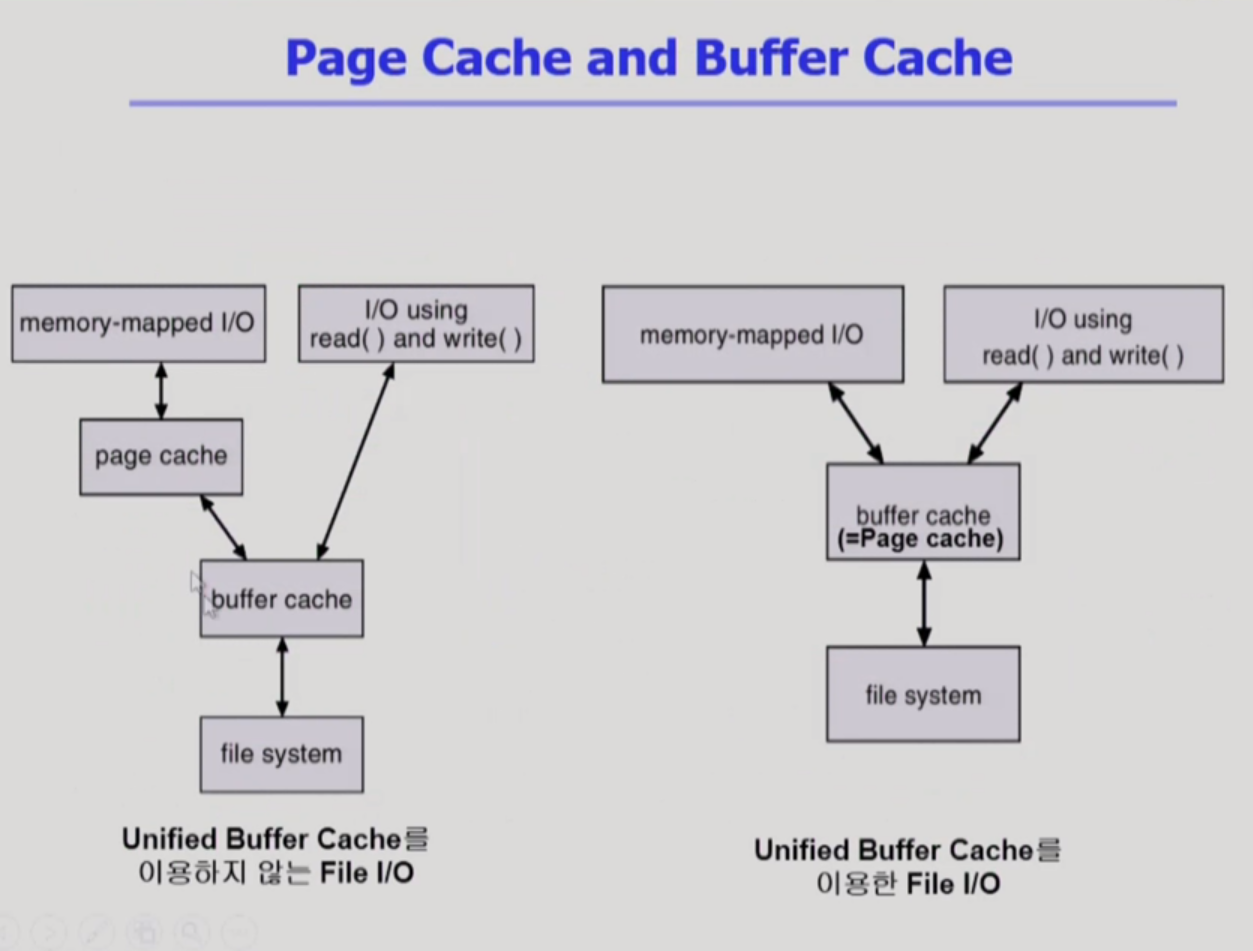
Page Cache and Buffer Cache
Page Cache
- Virtual memory의 paging system에서 사용하는 page frame을 caching의 관점에서 설명하는 용어
- Memory-Mapped I/O를 사용하는 경우 file의 I/O에서도 page cache 사용
Memory-Mapped I/O
- File의 일부를 virtual memory에 mapping
- 매핑시킨 영역에 대한 메모리 접근 연산은 파일의 입출력을 수행하게 함
Memory-Mapped I/O를 사용하는 경우 요청 데이터가 메모리에 없는 경우 스왑 영역이 아닌 파일 시스템을 접근한다.
Buffer Cache
- 파일 시스템을 통한 I/O 연산은 메모리의 특정 영역인 buffer cache 사용
- File 사용의 locality 활용 (지역성: 특정 부분 집중적으로 사용하는 특성)
- 한 번 읽어온 block에 대한 후속 요청 시 buffer cache에서 즉시 전달
- 모든 프로세스가 공용으로 사용
- Replacement algorithm 필요 (LRU, LFU 등)
Unified Buffer Cache
- 최근의 OS에서는 기존의 buffer cache가 page cache에 통합됨