
학교 다닌 지 얼마나 됐다고 벌써 졸업 프로젝트라니.. 학교를 벗어나기 싫은 마음과 그냥 쉽게 졸업 시켜줬으면 좋겠다는 마음이 공존하는 시기입니다. 하지만 졸업 후 취준은 더 힘들테니 열심히 해야죠😇🔥🔥
블로그를 만든지는 꽤 됐지만 기술 블로그라는 것은 처음 써봐서 어떻게 써야 할 지 갈피가 좀 안잡히지만, 일단 시작해보겠습니다.

동아리 언니가 알려준 이모티콘. 티스토리에 이모티콘이 있다는 걸 이번에 처음 알았어요..
Intro
저희 팀의 프로젝트는 [RPA와 딥러닝을 이용한 유사얼굴 탐색 서비스] 입니다. 말 그대로 RPA를 이용해 웹에서 스크래핑한 이미지와 딥러닝 모델을 사용하여 유사 얼굴을 탐색하는 서비스인데요.
저희는 이 기술을 '지인능욕' 범죄에 적용하면 좋겠다고 생각해서 지인능욕 범죄가 제일 빈번하게 일어나는 트위터를 대상으로 '#지인능욕' 과 같은 해시태그를 검색했을 때 나오는 이미지를 RPA를 이용해 스크래핑하여 사용자가 입력한 사진의 얼굴과 face verification을 진행하여 유사한 얼굴이라고 판단되는 이미지를 보여주기로 초기에 계획했습니다.
이때 트위터를 대상으로 사전조사를 해보았을 때 검색을 통해 나오는 이미지 중에 얼굴이 제대로 나오지 않거나 훼손(합성)된 경우가 존재하기 때문에 이러한 이미지를 커버하기 위해서는 이미지 매칭(feature matching)을 추가로 이용하는 것이 좋겠다는 의견이 나왔습니다.
그리고 중간발표에서 교수님께서 주셨던 피드백 중, 악용할 경우가 있으니 본인인증이 필요하지 않겠냐는 조언을 받아들여 팀원들끼리 의논한 결과 사용자에게 얼굴인식을 위한 이미지를 입력 받을 때 사용자가 이미지를 바로 업로드하는 것이 아니라 캠을 이용하여 사용자가 직접 얼굴을 동영상으로 찍고 해당 동영상에서 이미지를 추출하여 얼굴 인식 모델에 사용하는 방법을 사용하는 방식으로 본인인증을 받는 방법을 고안했습니다.
서론이 길었지만.. 그래서 제가 맡은 부분은 바로 이 본인인증을 구현하기 위한 기술요소를 검증하는 것입니다😎
해야 할 일은 크게 두 단계로 나누어집니다.
- 웹캠에서 프레임 추출하기
- 추출한 프레임을 얼굴 인식 모델에 넣어 정확도 검증
1. 파이썬의 OpenCV를 사용하여 웹캠에서 프레임 추출하기 (extract frame from videos using OpenCV in Python)
2. 추출한 프레임을 이용해서 얼굴 인식 모델에서 정확도가 나오는 지 검증
1. 웹캠에서 프레임 추출하기 (Extract Video Frames from Webcam and Save to Images using OpenCV in Python)
동영상에서 프레임을 추출하기 위한 툴은 여러가지가 있습니다. (VLC, ffmpeg, openCV 등등..)
이 중에서 저는 파이썬에서 사용할 수 있는 OpenCV를 사용하기로 했습니다.
OpenCV는 Open Source Computer Vision Library로 실시간 이미지 프로세싱에 중점을 둔 라이브러리입니다. 얼굴을 인식하고, 물체를 식별하고 이미지를 결합하는 등의 작업이 가능합니다.
먼저 파이썬에서 OpenCV를 이용하기 위해 opencv를 설치해야 하는데 pip install을 사용하여 간단히 설치할 수 있습니다. cmd를 열어 아래의 코드를 입력하여 opencv를 설치해주었습니다.
pip install opencv-python파이썬에서 opencv의 버전을 출력해서 설치가 잘 되었는지 확인할 수 있습니다.
import cv2
print(cv2.__version__)
웹캠에서 프레임을 추출하여 이미지로 저장하는 프로세스는 네 단계로 나뉩니다.
- frame을 추출할 비디오 파일 가져온다 👉 웹캠을 사용해서 바로 찍은 영상을 사용
- 영상을 frame by frame으로 읽는다
- 각 frame을 cv2.imwrite() 를 이용해 저장
- VideoCapture를 Release하고 모든 윈도우 close
코드는 다음과 같습니다.
import cv2
# 1. frame 추출에 사용할 비디오 파일 가져오기
# Opens the inbuilt camera of laptop to capture video.
cap = cv2.VideoCapture(0)
i = 0
while(cap.isOpened() and i<=100):
# 2. 영상을 frame by frame으로 읽는다
ret, frame = cap.read()
# This condition prevents from infinite looping
# incase video ends.
if ret == False:
break
# webcam으로 찍히는 모습 보여줌.
cv2.imshow("preview",frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 3. 각 frame을 cv2.imwrite() 를 이용해 저장
# Save Frame by Frame into disk using imwrite method
cv2.imwrite('Frame'+str(i)+'.jpg', frame)
i += 1
# 4. VideoCapture를 Release하고 모든 윈도우 close
cap.release()
cv2.destroyAllWindows()cv2.VideoCapture(<path_of_video>) 를 사용하면 해당 path에 있는 video파일을 불러올 수 있고, cv2.VideoCapture(0) 를 사용하면 내장된 카메라(보통 웹캠으로 연결)를 사용해서 바로 영상을 받아올 수 있습니다. 웹캠이 1개만 부착되어 있으면 0, 2개 이상이면 첫 웹캠은 0, 두번째 웹캠은 1으로 지정합니다.
그리고 내가 찍히는 모습을 확인할 수 있도록, cv2.imshow() 메소드를 통해 preview 화면을 보여주도록 했습니다. 처음에 cv2.imshow() 만 입력했을 때는 "응답없음" 오류가 떴는데, if cv2.waitKey(1) & 0xFF == ord('q'): break; 조건문을 추가하니 오류없이 화면이 잘 실행되었습니다🤔
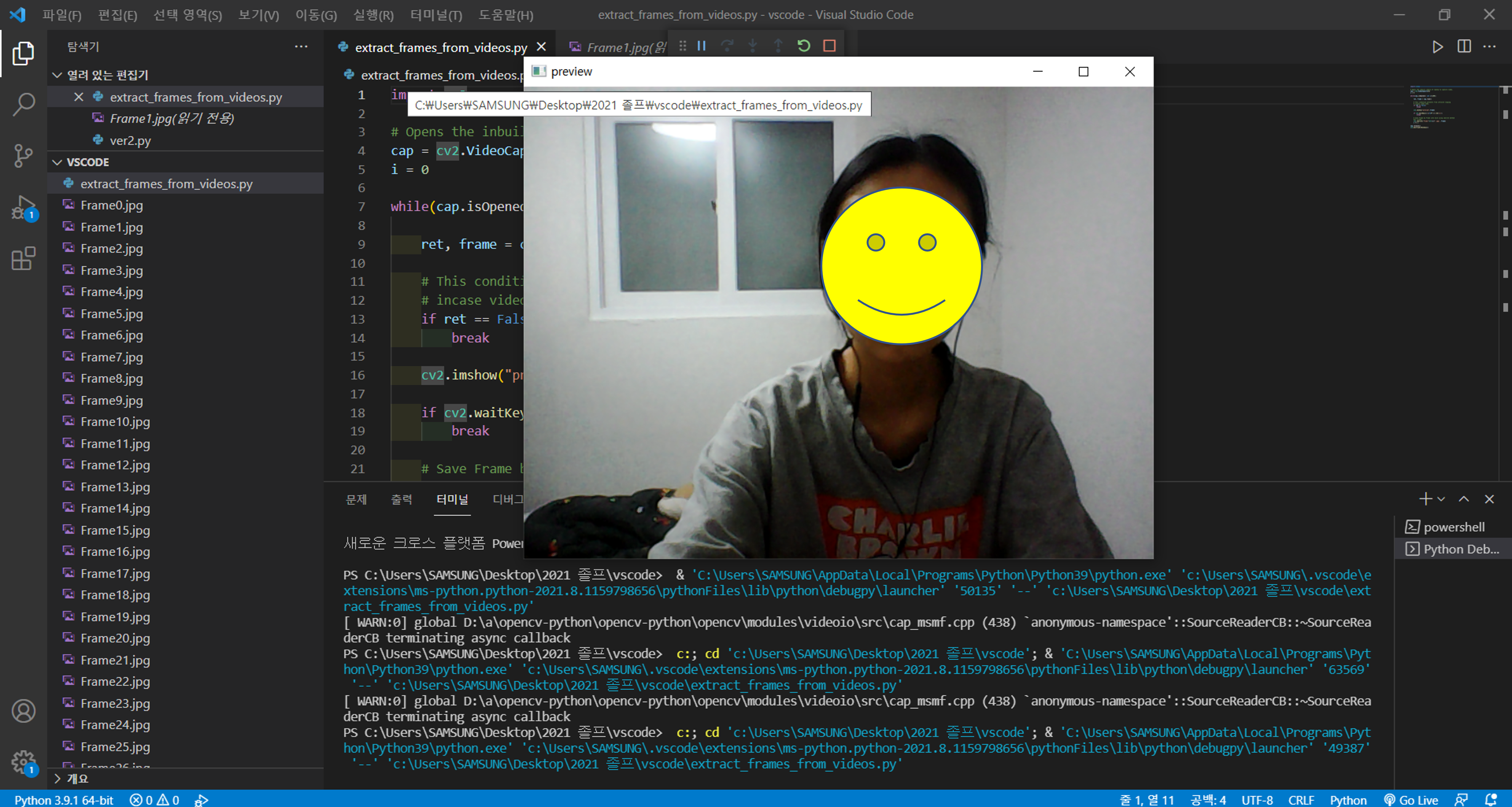
일단 100개의 frame을 추출하도록 코드를 작성했는데 저장된 이미지를 보니 초반 사진들은 처음 웹캠이 켜지느라 그런건지 너무 어둡게 나왔습니다. 넉넉하게 30번째 프레임부터 밝기가 일정해지는 것 같습니다.

저 후줄근한 도라에몽 티는.. 대학교 1학년 때부터 입었던 내 애착 티셔츠(?) 하지만 나는 사실 도라에몽을 좋아하지 않는다. 그냥 있어서 입는 거다.
2. 추출한 프레임을 얼굴 인식 모델에 넣어 정확도 검증
딥러닝을 활용한 얼굴 인식은 연구도 많이 되어 있고 검증이 이미 완료된 많은 모델들이 있습니다.
이 중 저는 python에서 제공하는 library인 Deepface를 이용할 것입니다.
Deepface is a lightweight face recognition and facial attribute analysis (age, gender, emotion and race) framework for python. It is a hybrid face recognition framework wrapping state-of-the-art models: VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace and Dlib. Those models already reached and passed the human level accuracy. The library is mainly based on TensorFlow and Keras.
https://github.com/serengil/deepface
GitHub - serengil/deepface: A Lightweight Face Recognition and Facial Attribute Analysis (Age, Gender, Emotion and Race) Library
A Lightweight Face Recognition and Facial Attribute Analysis (Age, Gender, Emotion and Race) Library for Python - GitHub - serengil/deepface: A Lightweight Face Recognition and Facial Attribute Ana...
github.com
코드 작성은 구글 colab을 이용했습니다.
본격적으로 코드 작성에 들어가기 전에 colab과 구글 드라이브를 연동해 놓는 것이 편합니다. 처음엔 이 방법도 몰라서 헤맸는데..😅
사실 검색해보면 친절하게 스크린샷까지 잘 찍어놓은 글이 많이 나오는데 그냥 코드 몇 줄만 적으면 되는 간단한 과정입니다.
from google.colab import drive
drive.mount('/content/drive')그리고 창이 뜨면 연동할 계정을 선택하고 권한을 허용합니다.
그러면 이렇게 폴더가 드라이브와 연동된 것을 확인할 수 있습니다.
그리고 deepface 라이브러리를 사용하려면 먼저 설치를 해야 합니다. 설치는 pip를 통해 간단히 할 수 있습니다.
!pip install deepface
자, 그럼 모든 준비는 끝났습니다(?)
간단하게 face detection과 face verification을 진행해 볼 것입니다. 일반 연예인 사진으로 먼저 확인을 하고, 웹캠에서 추출한 frame 이미지로도 정확도가 나오는지 확인을 해 볼 것입니다.
일단 설치를 했으니 import를 해야 하겠죠..
from deepface import DeepFaceDeepFace에는 DeepFace.verify()라는 function이 있습니다. 이 함수로 두 개의 이미지에 대한 face verification을 진행할 수 있는데, 이 함수 안에 face detection 과정도 포함됩니다.
하지만 우리는 face detection도 확인하기 위해 따로 출력을 해볼 것입니다.
먼저 비교를 위해 사용할 샘플 데이터 이미지의 경로를 입력합니다.
img1_path = "/content/drive/MyDrive/sampledata/jennie/jennie1.jpg"
img2_path = "/content/drive/MyDrive/sampledata/jennie/jennie2.jpg""위에서 드라이브와 마운트를 해놓았기 때문에 그냥 드라이브 경로를 입력해주면 됩니다.
face detection을 하는 함수는 DeepFace.detectface() 입니다.
결과를 출력하기 위해 matplotlib.pyplot 도 import를 해줍니다.
import matplotlib.pyplot as plt
img1 = DeepFace.detectFace(img1_path)
img2 = DeepFace.detectFace(img2_path)
plt.imshow(img1)
plt.imshow(img2)결과는 다음과 같습니다.
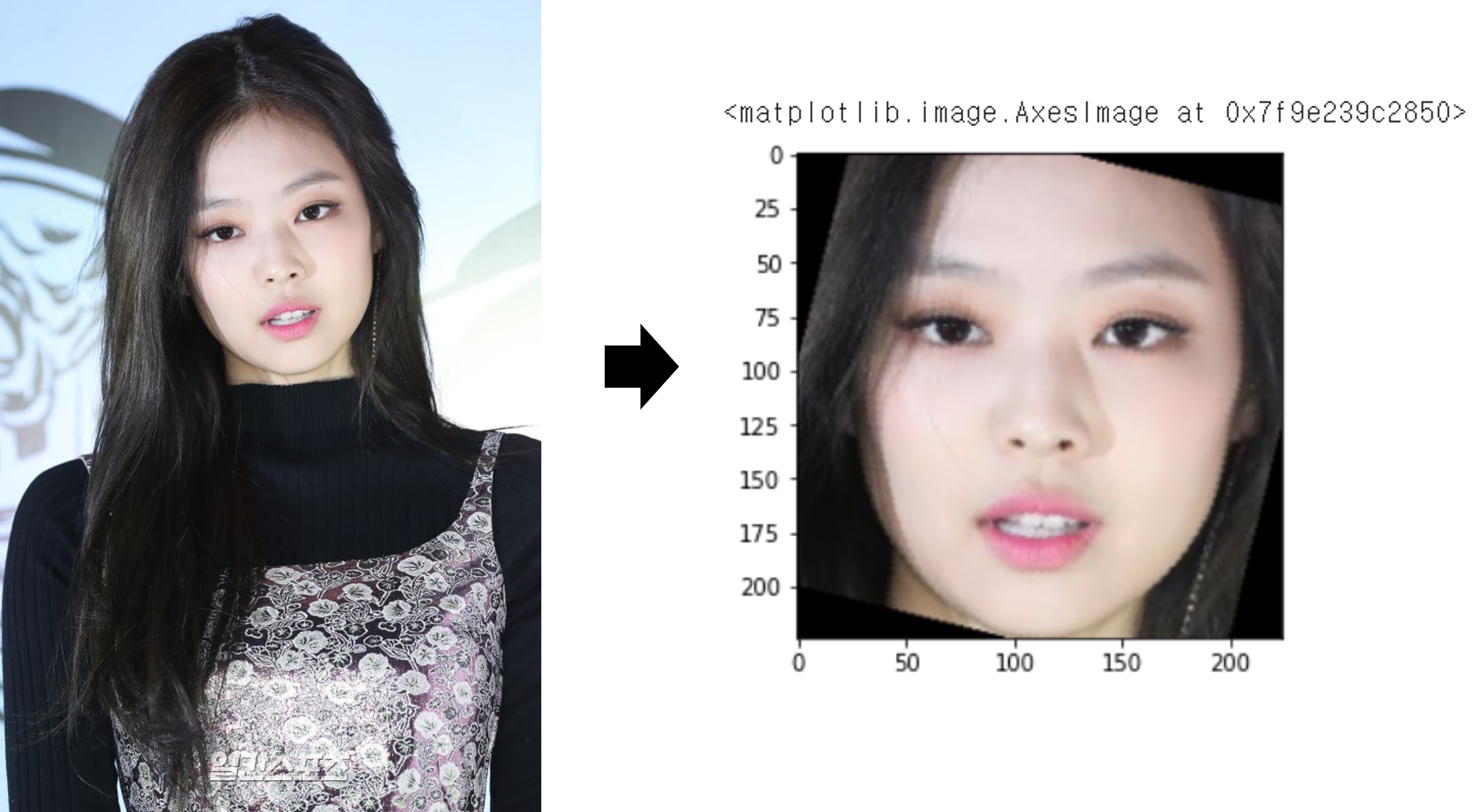

보면 알겠지만, face alignment도 함께 적용되어 각도까지 맞춰줍니다.
자 그럼 이제 verify 함수에 넣어봅시다!
verify 함수는 다음과 같이 구성되어 있습니다.
def verify(img1_path,
img2_path='',
model_name='VGG-Face',
distance_metric='cosine',
model=None,
enforce_detection=True,
detector_backend='opencv',
align=True, prog_bar=True, normalization='base')
models = ["VGG-Face", "Facenet", "Facenet512", "OpenFace", "DeepFace", "DeepID", "ArcFace", "Dlib"]
metrics = ["cosine", "euclidean", "euclidean_l2"]일단 VGG-Face 모델을 사용하여 verify를 진행해보았습니다.

verified 값이 True로 두 이미지의 얼굴을 동일 얼굴로 잘 인식한 결과를 보여줍니다.
그래서 제일 정확도가 높다던 Facenet과 Facenet512 모델을 사용해 봤는데...



이게 웬걸... 거리도 더 멀게 나오고 Facenet152 모델의 경우에는 False로 나오네요....
그렇다면 distance_metric를 바꿔봅시다!!

다행히 distance_metric 를 바꾸니 verified 값이 True로 나오긴 합니다.. 실제 본격적인 프로젝트 개발을 진행할 때는 모델 뿐만 아니라 distance_metric도 함께 고려해서 최상의 성능을 내는 조합을 잘 찾아야겠습니다..😂
아무튼!!
모델이 잘(?) face detection과 face verification을 수행하는 것을 확인했으니 이제 드디어 웹캠에서 추출한 frame 이미지를 넣어볼 차례입니다. 비교할 이미지를 뭘로 해야하나.. 하다가 그냥 기본 카메라로 셀카를 찍었습니다. (원래도 워낙 사진을 안찍어서 사진이 없다) 그리고 뭔가 너무 비슷한가 싶어서 화장하고 찍은 민증 사진도 넣어 보았습니다..ㅋㅋ
코드는 위에서 봤던 코드와 같고 이미지 경로만 다르니 생략하겠습니다.
먼저 face detection을 진행했을 때는 웹캠에서 추출한 frame도 결과가 잘 나오는 걸 확인할 수 있었습니다.
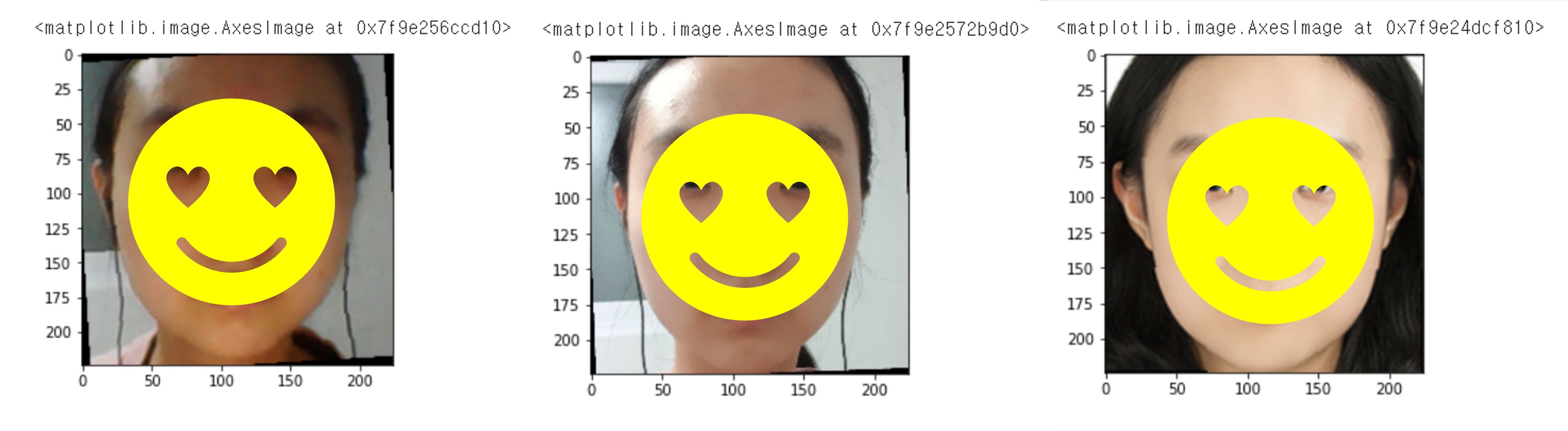
제일 왼쪽이 웹캠에서 추출한 frame이고 두번째 사진이 기본 셀카로 찍은 사진, 마지막 사진이 민증 사진입니다.
그리고 위에서 했던 것처럼 VGG-Face, Facenet, Facenet512 모델을 사용해서 face verification을 진행해보았습니다.
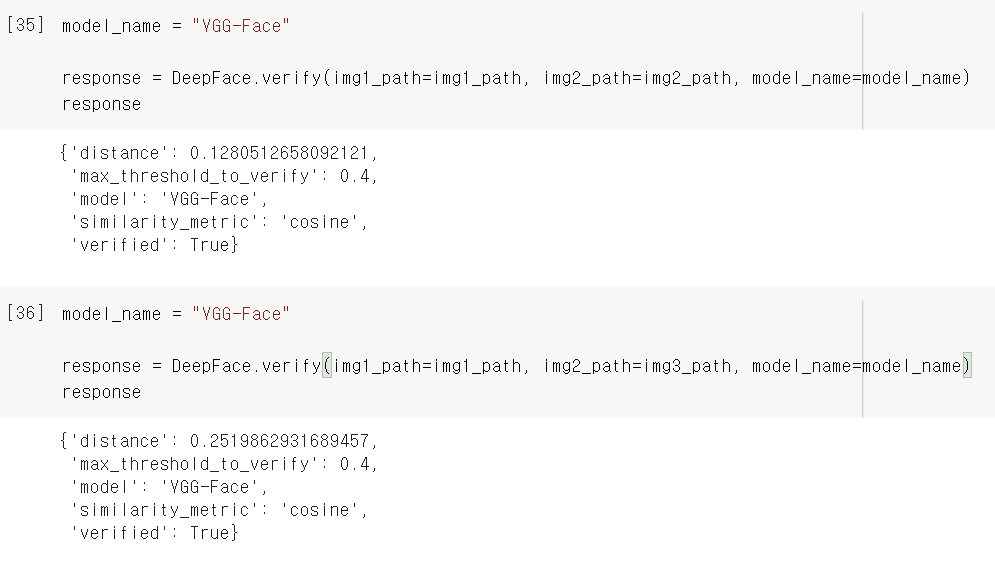
먼저 VGG-Face 모델을 이용해서 셀카(img2)와 비교했을 때는 거리도 가깝게 나오고 verified도 True로 잘 나왔습니다. 그리고 민증 사진(img3)과 비교할 때는 솔직히 별로 기대하지 않았는데 True로 잘 나와서 놀랐습니다!
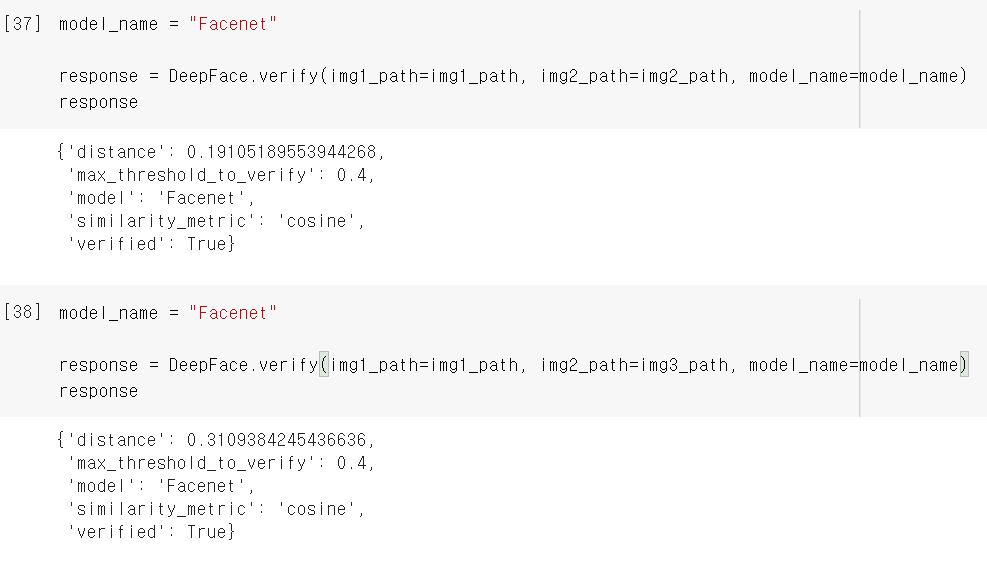
다음으로 Facenet 모델을 사용했을 때도 img2, img3와 비교했을 때 모두 같은 얼굴이라고 잘 인식하는 걸 볼 수 있었습니다!
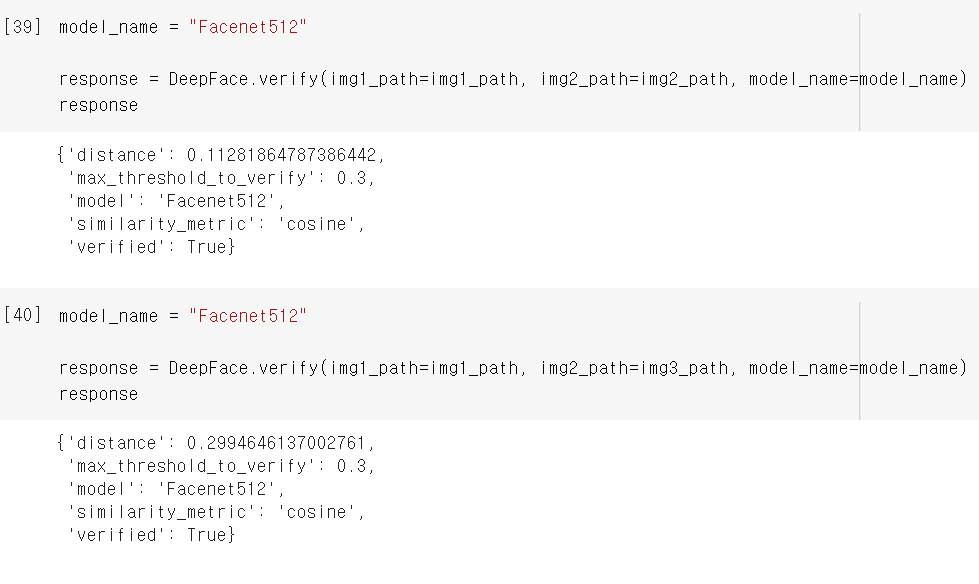
그리고 아까 제대로 나오지 않았던 Facenet512 모델을 썼는데..! 다행히 둘 다 결과가 잘 나오는 걸 확인할 수 있었습니다. 다만 img3랑 비교한 경우에는 distance가 아주 아슬아슬하게 threshold 안에 들어왔네요..ㅎㅎ
Conclusion
웹캠에서 frame을 추출한 것을 얼굴 인식 모델의 input으로 넣어도 정확도가 떨어지지 않는다는 것을 확인할 수 있었습니다!

물론.. 내가 얼굴이 잘나오게 잘 찍었으니 그런 걸 수도...
그래서 더 고려해봐야 할 점은, 사용자가 정면 얼굴이 잘 나오게 화면에 얼굴을 비추도록 안내를 해야 하고, 만약 face detection이 제대로 되지 않는다면 사용자에게 얼굴을 더 가깝게 하라던지, 조명을 밝게 해달라던지 하는 메시지를 출력하는 방향으로 가야 할 것 같습니다.
그리고 얼굴 인식 모델의 정확도 개선을 위한 검증도 실제로 트위터 상의 이미지와 비교하면서 계속 진행해야 합니다..!
우리 팀이 정말 일찍부터 아이디어 회의도 열심히 하고.. 중간에 피드백 받고 아예 갈아엎을까 하고 고민도 많이 했고.. 정말 회의 시간마다 꽉꽉 채우고 다들 열심히 하는데.. 열심히 한 만큼 만족스러운 결과물을 얻을 수 있었으면 좋겠습니다🔥
사실 이거 말고도 여러개 해봤는데...ㅠㅠ 아까우니 따로 글이라도 다시 써야겠다.. (언제? 몰라..)
'프로젝트 > 캡스톤 디자인 프로젝트' 카테고리의 다른 글
| 얼굴 인식 모델 fine-tuning을 위한 데이터 수집 (크롤러 개발 + 전처리) (0) | 2022.05.14 |
|---|---|
| 스프링부트+JPA (0) | 2022.01.10 |